TiVA:
Time-Aligned Video-to-Audio Generation
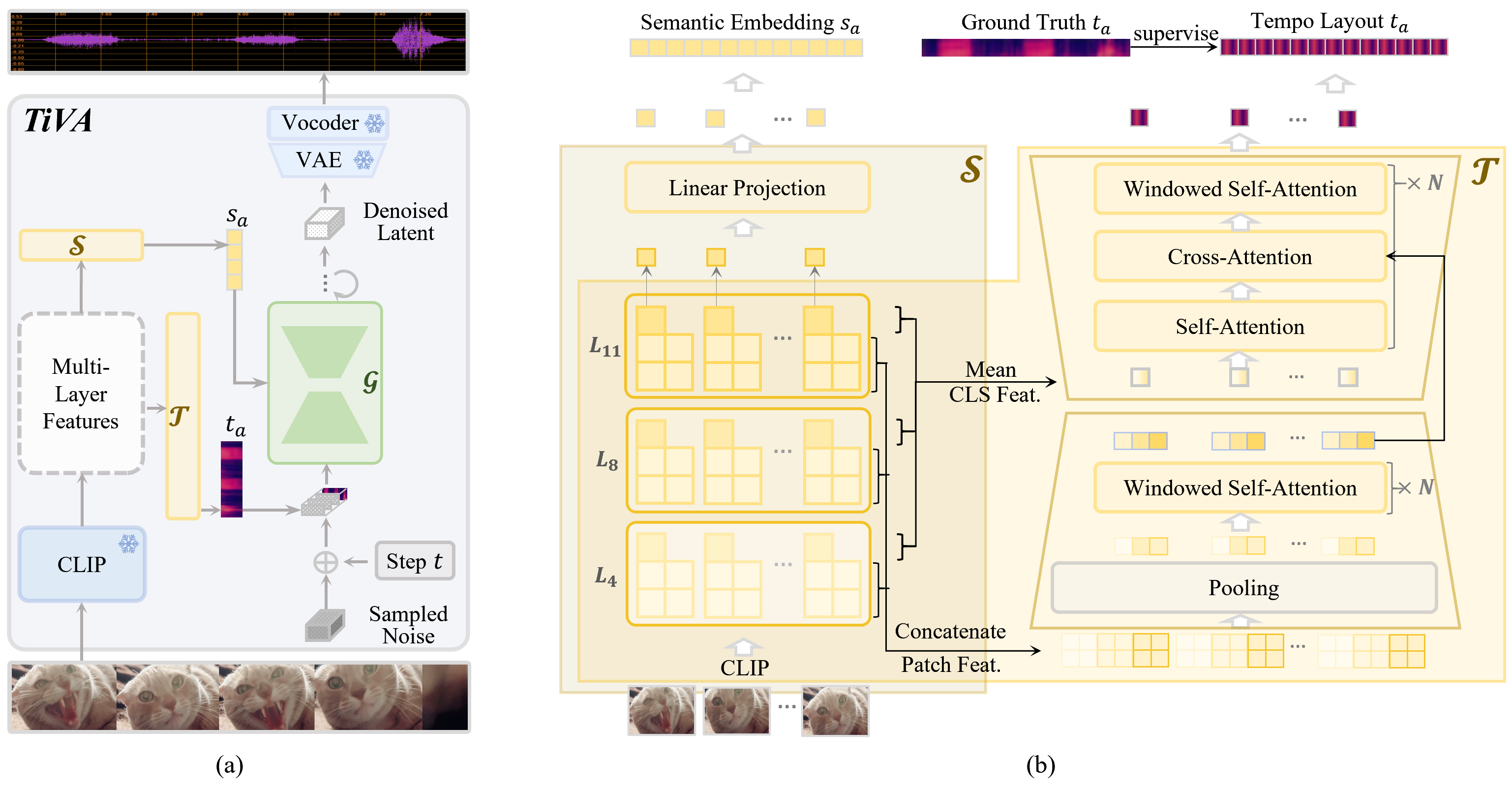
Video-to-audio generation is crucial for autonomous video editing and post-processing, which aims to generate high-quality audio for silent videos with semantic similarity and temporal synchronization. However, most existing methods mainly focus on matching the semantics of the visual and acoustic modalities while merely considering their temporal alignment in a coarse granularity, thus failing to achieve precise synchronization on time. In this study, we propose a novel time-aligned video-to-audio generator, called TiVA, to achieve semantic matching and temporal synchronization jointly when generating audio. Given a silent video, our method encodes its visual semantics and predicts a tempo layout separately. Then, leveraging the semantic latent codes and the predicted tempo layout as condition information, it learns a latent diffusion-based audio generator. Comprehensive objective and subjective experiments demonstrate that our method consistently outperforms state-of-the-art methods on semantic matching and temporal synchronization precision.